
Introduction Gremlin lets you run multiple Chaos Engineering experiments in a single workflow called a Scenario…

Andre Newman
Sr. Reliability Specialist

In this tutorial, we'll show you how to run a Chaos Engineering experiment on a serverless application using Failure Flags. Failure Flags lets you run experiments on applications and services, particularly those that limit access to the underlying infrastructure, such as AWS Lambda, Azure Functions, Google Cloud Functions, and others. This includes:
For this tutorial, we'll run a Node.js application on AWS Lambda. These same general steps apply to all of our supported platforms and languages, which you can learn about in our documentation.
This tutorial will show you how to:
Before starting this tutorial, you’ll need the following:
In this step, you'll create a Node.js application and add a Failure Flag. This is a simple application that responds to HTTP requests with the current timestamp and the time needed to process the response.
Create a new Node.js project:
1npm init --yes
Add Failure Flags to your project dependencies by running the following command:
1npm i --save @gremlin/failure-flags
Create a new file named index.js with the following code:
1const gremlin = require("@gremlin/failure-flags");23module.exports.handler = async (event) => {4 start = Date.now();56 await gremlin.ifExperimentActive({7 name: "http-ingress", // name of the failure flag.8 labels: {9 method: event.requestContext.http.method,10 path: event.requestContext.http.path,11 },12 });1314 return {15 statusCode: 200,16 body: JSON.stringify(17 {18 processingTime: Date.now() - start,19 timestamp: event.requestContext.time,20 },21 null,22 223 ),24 };25};
Lines 6—12 are where we define our Failure Flag. This is an entrypoint where we can inject faults into the application, but it won't do anything unless we have an experiment running. For example, if we run an experiment that introduces 500ms of latency, the application will run normally up to this point, then delay execution by 500ms before continuing. If there are no active experiments targeting this application, nothing will happen and the code will run normally.
At a minimum, we need to give this Failure Flag a name using the name attribute. This example uses http-ingress, but you can change this to whatever you'd like. You can also add custom labels for more advanced targeting (i.e., targeting specific kinds of application traffic), but that's beyond the scope of this tutorial. You can learn more in the documentation.
We need a way to authenticate our Failure Flag with Gremlin. We can do this by creating a file with our Gremlin team ID and secret keys and deploying it alongside our Lambda function. This file can also contain additional labels like the application name, version, region, etc.
config.yaml.us-east-2 region and the http-ingress project, letting you target all functions running in us-east-2 or that belong to the http-ingress project:1labels:2 datacenter: us-east-23 project: http-ingress
The configuration file supports other options, but the defaults are all you need for this tutorial.
Now we get to deploy our application to Lambda. This step also includes deploying the Failure Flags Lambda layer. So far, we've been focused on the SDK, which is responsible for injecting faults into the application. The layer is responsible for communicating with Gremlin's backend servers and orchestrating experiments. The specifics of deploying to Lambda go beyond the scope of this tutorial, so we'll link to the AWS docs where necessary.
1FAILURE_FLAGS_ENABLED=12GREMLIN_LAMBDA_ENABLED=13GREMLIN_CONFIG_FILE=/var/task/config.yaml
arn:aws:lambda:us-east-2:044815399860:layer:gremlin-lambda-x86_64:13.
Now that everything's set up, we can start running experiments!
1{ "latency": 1000 }

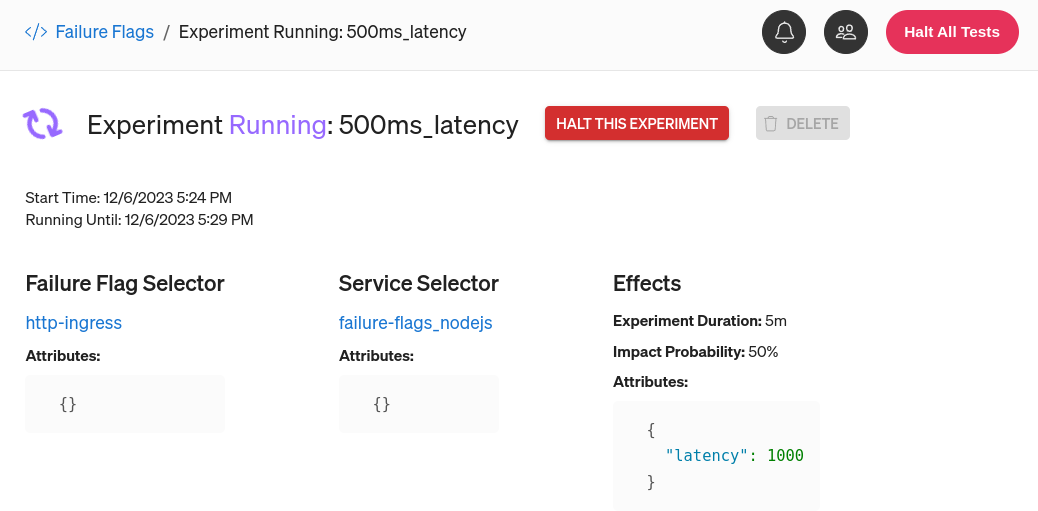
While the experiment runs, open your Lambda URL in a web browser or a performance testing tool. How is it responding? How noticeable is the latency? Is the amount of latency more than you expected (longer than one second)? If so, why do you think that is? How might you rearchitect this app so the latency doesn't have as big of an impact?

When you're finished making observations and want to stop the experiment, simply click Halt this experiment in the Gremlin web app. Remember to throttle or delete your Lambda function when you're done!
Congratulations on running your first serverless Chaos Engineering experiment on AWS Lambda with Gremlin! Now that you have Failure Flags set up, try running different kinds of experiments. Add jitter to your network latency, impact a larger or smaller percentage of traffic, generate exceptions, or perform a combination of effects. For more advanced tests, you can even define your own experiments or inject data into your app.
If you want to learn about the different configuration options available in the Failure Flags SDK, or to see how it works, check out our Github repository. Failure Flags also has language-specific features, but this is currently only available for Go.
If you'd like to try Failure Flags outside Lambda, we also have a sidecar for Kubernetes. Just deploy the sidecar, then define and run your experiment. Remember that Failure Flags has no performance or availability impacts on your application when not in use, so don't be afraid to add it to your applications.
Gremlin empowers you to proactively root out failure before it causes downtime. See how you can harness chaos to build resilient systems by requesting a demo of Gremlin.
Get started