

Introduction In this tutorial, we'll show you how to run a Chaos Engineering experiment on a serverless application…

Andre Newman
Sr. Reliability Specialist

Gremlin is a simple, safe and secure service for performing Chaos Engineering experiments through a SaaS-based platform. Cassandra is Apache’s database that is scalable and high availability without compromising performance. It’s open source, distributed and decentralized/distributed storage system.
This tutorial will teach you how to do Chaos Engineering on Cassandra Using Gremlin.
This tutorial will show you how to use Gremlin and Cassandra
Before you begin this tutorial, you’ll need the following:
First, ssh into your host and add the gremlin repo:
1ssh username@your_server_ip
1echo "deb https://deb.gremlin.com/ release non-free" | sudo tee /etc/apt/sources.list.d/gremlin.list
Import the GPG key:
1sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys C81FC2F43A48B25808F9583BDFF170F324D41134 9CDB294B29A5B1E2E00C24C022E8EF3461A50EF6
Install the Gremlin agent:
1sudo apt-get update && sudo apt-get install -y gremlin gremlind
First, make sure you have a Gremlin account (sign up here). Then, we will grab the credentials needed to authenticate the agent we just installed. Log in to the Gremlin App using your Company name and sign-on credentials. (These were emailed to you when you signed up to start using Gremlin.) Click on the right corner circular avatar, selecting “Company Settings”.

Then, select the team you need. The ID you’re looking for is found under Configuration as “Team ID” click on your Team. Make a note of your Gremlin Secret and Gremlin Team ID.

Now, on your host, we will initialize Gremlin and follow the prompts.
1gremlin init
Use the credentials you have saved from the last step.
In this step, you’ll be installing Cassandra onto your host. First, Install add the Apache repository of Cassandra:
1echo "deb http://www.apache.org/dist/cassandra/debian 311x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
Add the Apache Cassandra repository keys:
1curl https://www.apache.org/dist/cassandra/KEYS | sudo apt-key add -
Update the repositories:
1sudo apt-get update
Install Cassandra:
1sudo apt-get install cassandra
Verify it has been setup properly and has been started:
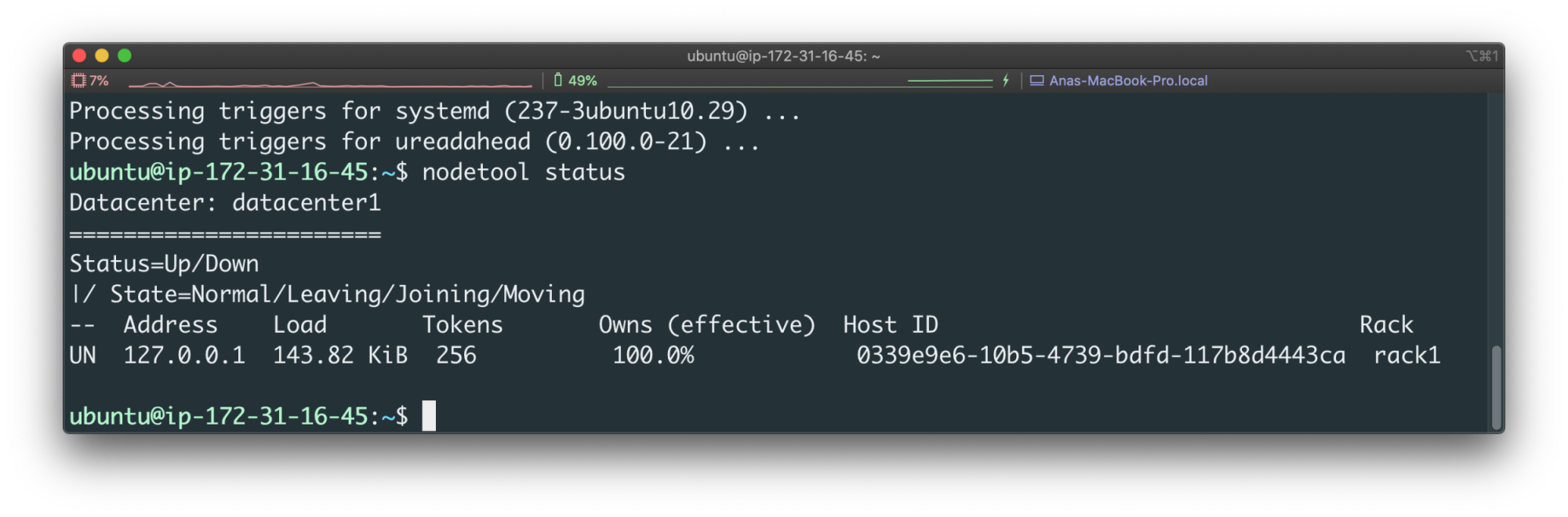
1nodetool status
Your output should look similar to this:
In this step, you’ll add some data to Cassandra using Cassandra Query Language. For this tutorial we are going to be the cli tool, cqlsh. By default, Cassandra sets up a “Test Cluster” for us.
Start the cli:
1cqlsh
You can learn about the default configuration via:
1DESCRIBE CLUSTER
We are going to create our first Keyspace. In Cassandra a Keyspace is a namespace that defines data replication on nodes. We are going to be using SimpleStrategy for replication. Read more about it and other options here.
1CREATE KEYSPACE user_db WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
Verify the creation:
1DESCRIBE KEYSPACES
Select the newly created keyspace:
1USE user_db;
Create a table called user:
1CREATE TABLE user (2 id int PRIMARY KEY,3 age int,4 name text,5 surname text,6 );
Verify the table has been created:
1select * from user;
Now let’s add some data into this table:
1INSERT INTO user (id, age, name, surname) VALUES (1, 21, 'ana', 'medina');
Verify the information table has been created:
1select * from user;
We should see a table that looks like this:

To exit from cqlsh, just type exit. We will be now set up iostat, this is a linux command used for monitoring system I/O device loading, this is included when you install systat, a performance monitoring tool for Linux. On your host install systat:
1sudo apt install sysstat
For our first Chaos Engineering experiment we are going to be running a Disk Chaos Engineering experiment. This will be consuming disk space. Our hypothesis is, “When we consume 100% of our disk, we won’t be able to add entries to Cassandra.”
For monitoring this experiment we are going to run:
1while sleep 2; do df --o; done
What we see below is the steady state of the application:

Going back to the Gremlin UI, select Attacks from the menu on the left and press the green “New Attack” button. We will be choosing the host we installed Gremlin on:

We will now go over to choosing the Gremlin. We will run a resource Chaos Engineering Attack, select “Resource” and choose “Disk” from the options. We will make the length 200 seconds, ask it to consume the Volume at 100 percent. We are then going to press “Show Advanced Options” and change the value of workers to 4 and make the block size 10000KB. Then press the green button to unleash the Gremlin.

We can see on our monitoring that dev/xvda1 is running at 100% consumption.

Were you able to add entries into Cassandra?
Can you browse all of them?
We are going to create our second Chaos Engineering experiment. Performance is something we constantly need to keep in mind when using tools like Cassandra. We are going to run a Chaos Engineering experiment to learn more about how this host and implementation of Cassandra holds up to various disk/writes. Our hypothesis is, “When we consume I/O resources, Cassandra will still be usable and we will monitor this with iostat too.”
Going back to the Gremlin UI, select Attacks from the menu on the left and press the green “New Attack” button. We will be choosing the host from the list.

We will now go over to choosing the Gremlin. We will run a resource Chaos Engineering attack, select “Resource” and choose “IO” from the options. We will make the length 300 seconds, keep the default Root Directory of /tmp and Mode of rw (read and writes). We are going to select “Show Advanced Options” and set it to run 100 Workers (The number of IO workers to run concurrently), with a Block Size (Number of Kilobytes (KB) that are read/written at a time) of 8000KB and a Block Count (The number of blocks read/written by workers) of 20. Then press the green button to Unleash the Gremlin.

As the experiment start running iostat and have it refresh every 1 seconds, on your host run:
1iostat -x 1

As the experiment is running along with iostat, we have also tried a few more entries, we see that they have been added without any problems.

We also want to make sure to look at our monitoring of our IO consumption on the host using iostat:

Since we saw that this Cassandra setup handled this IO experiment very well, we will run a third Chaos Engineering experiment.
We are going to expand its Blast Radius. What does that mean? Blast radius is the subset of a system that can be impacted by an attack. We saw what would happen when using a Block Size of 8000KB, but what if we made the Block Size larger, following the real-world example of uploading files to a file sharing service? We are going to simulate files of 50MB. Our hypothesis is, “When we consume more I/O resources, Cassandra will still be usable and we will monitor this with iostat too.”
Going back to the Gremlin UI, select Attacks from the menu on the left and press the green “New Attack” button. We will be choosing the host from the list.
We will now go over to choosing the Gremlin. We will run a resource Chaos Engineering attack, select “Resource” and choose “IO” from the options. We will make the length 300 seconds, keep the default Root Directory of /tmp and Mode of rw (read and writes). We are going to select “Show Advanced Options” and set it to run 100 Workers (The number of IO workers to run concurrently), with a Block Size (Number of Kilobytes (KB) that are read/written at a time) of 50000KB and a Block Count (The number of blocks read/written by workers) of 20. Then press the green button to Unleash the Gremlin.
Just like the last experiment, we want to make sure to go back and look at the monitoring we are doing with iostat:
We also want to test how Cassandra is handling this Chaos Engineering experiment, we see that we are able to add new entries but it’s 2 seconds slower than last experiment. Chaos Engineering experiments like this allow you to make sure you can handle a high load of users trying to use your application and for them to have great experience. For the example of a file file-sharing service, you want to make your user is able to upload files at a timely speed as well as be able to view and delete the file as quickly as possible.
Congrats! You’ve now run a few Chaos Engineering experiments for Cassandra. Where you able to learn something new about your Cassandra configuration? There are many other Chaos Engineering experiment you can run to focus on Cassandra resiliency. One we see folks not run as often is we’re treating our hosts as kettle and not pets to verifying your Auto Scaling Groups groups. We have seen that some folks get scared on shutting down hosts, especially when dealing with data, but you want to make sure you’re constantly ready for all sorts of failure to occur. If you have any questions at all or are wondering what else you can do with this demo environment, feel free to DM me on the Chaos Slack: @anamedina (join here!).
Gremlin empowers you to proactively root out failure before it causes downtime. See how you can harness chaos to build resilient systems by requesting a demo of Gremlin.
Get started