
Companies will continue to struggle to implement good reliability practices if the only opportunity to improve are adjustments made after production failures.
We all want reliable systems, whether they be computer systems, mechanical systems, manufacturing, or information technology. Reliability has always been the aim. Equipment failures cost money. So do software failures.
Manufacturing operations have worked for ages on improving the reliability of their assembly lines. Information technology (IT) has done disaster recovery plans like evacuating to a hot site data center (we are not saying this is a bad thing, by the way), but is just now learning to have a similar focus as manufacturing on enhancing the reliability of computer systems.
The evolution toward systems reliability in IT is not yet as advanced. This article gives you some ideas to pursue and implement to help you along this path.
Reliability Is More Than Disaster Recovery
With so many constantly-changing parts, today’s computer systems include more opportunities for failure. We can no longer afford to only implement disaster recovery plans and wait until something fails, perhaps taking cues from failures to help us make some improvements. Talking about recovery time objectives (RTO) and recovery point objectives (RPO) won't create reliable systems. But something else will.
Sometimes, we think we understand technology, and we certainly do from a business perspective, the costs/benefits, the cadence of change that is most beneficial to drawing in customers, the value of having fast and responsive systems that keep running. It is easy to believe that resilience is automatically built into those systems. That is why we moved to the cloud, to microservices, to containers, and so on. Because these technologies give us more flexibility, we can move faster to ship more features for our customers.
Reliability is Not a Product of Configurability
Reliability is not an inherent quality of flexibility. But, complexity certainly is. The cost of flexibility and velocity is complexity, and this means the old reliability strategies need to adapt. With the rate of change in our systems, we must make a concerted effort to find and eliminate weaknesses and potential failures before they happen.
Most of our current system testing processes are like practicing a fire drill in a 100 year old building where the floor plans, fire escapes and exits are unmoving, fixed points that don’t change. In today’s modern “buildings” the floor plans change by the second and the height and width of the building ebb and flow to meet demand. Yesterday’s evacuation route is tomorrow’s fiery dead end. We can’t always conceive of what part of the system is more or less likely to fail. We need an updated perspective.
The development side of DevOps has had its cadence accelerated by a constant demand for new features, faster deployments, and transformed infrastructure to support these demands. The operations side of DevOps has not had adequate time and focus to keep up. Most companies are starting to realize this and are trying to accelerate implementing Site Reliability Engineering (SRE) practices.
Engineers Should Be More Than Firefighters
Adding to this mess is a tendency to use engineers to put out fires as quickly as possible, ignoring how often those fires occur and how many of them could be prevented. This leads to burn out as teams don’t have time to focus on helping the system mature in things like implementing automated disaster recovery, automated mitigation and failover schemes that prevent impacts from failures or potential that are detected early.
Being able to take needless work out of the system is more important than being able to put more work into the system.
Gene Kim
The Phoenix Project
The tendency to focus on the development side, deploying code frequently and iterating as issues occur is an unsustainable hinderance to reliability. The most useful thing we can do for company benefit and system reliability is to improve our process.
What Can Companies Do?
Let’s start by updating our fire drill methodology to match our constantly-changing architecture. Instead of assuming we have an up-to-the-minute accurate map of the building, begin by assuming we don’t.
We must give the operations side of DevOps its proper respect and focus. Provide our teams with the time they need to fix the things they learned about in the last failure. We don’t mean simply implementing quick fixes, but really taking the lessons learned and allowing them to system reliability by preventing that same failure from impacting the system again in the future. Let them create fire escapes that move along with the system, reacting to changes and being available even when our architecture is evolving rapidly.
Set an Occasional Fire Yourself
Next, as things stabilize a bit, explore our systems. What if we could safely introduce these failures at different points in your processes, but on our own terms? We could use what we learn to proactively design and modify software and infrastructure to handle those failures, preventing overall system downtime and customer impacts. Set a little fire somewhere and see if our fire escapes are adequate. If not, enhance them or build more. Preventing many production outages is possible, with the right attention.
Even when we have time or money constraints preventing us from redesigning our software or infrastructure, we do have the ability to create a more graceful experience for our customers.
We need to create a culture that reinforces the value of taking risks and learning from failure and the need for repetition and practice to create mastery.
Gene Kim
The Phoenix Project
Monitor, Be Alert and Aware
We can start with better observability by monitoring things we know have caused problems in the past and setting alerts at levels below where we have seen previous failures, giving time to compensate before customers are ever impacted.
We can combine that monitoring with simple Chaos Engineering experiments in small parts of our system, limiting the blast radius so that only what we are testing is impacted. What we learn from these experiments will help us enhance system reliability by enabling us to find and fix small things while they are still small.
Fix the Small Things
Fixing many small things adds up to major improvement over time. Taking the time to make the fixes seems difficult to schedule in, but when we do, we ultimately save ourselves more time than we spend. We can use that time to improve processes and reliability across our entire system.
Most of us find that we have time to better train new hires and get them up to speed more quickly. We find our teams gain greater confidence. It is faster and easier to learn how to do things like transfer a service or fix a found technical issue.
This sounds like maturity and it is attainable.
Introduce Controlled Failure to Prevent Unexpected Failure
Introducing controlled failure accelerates the adoption of good SRE practices and helps the operations side of our practices mature more quickly.
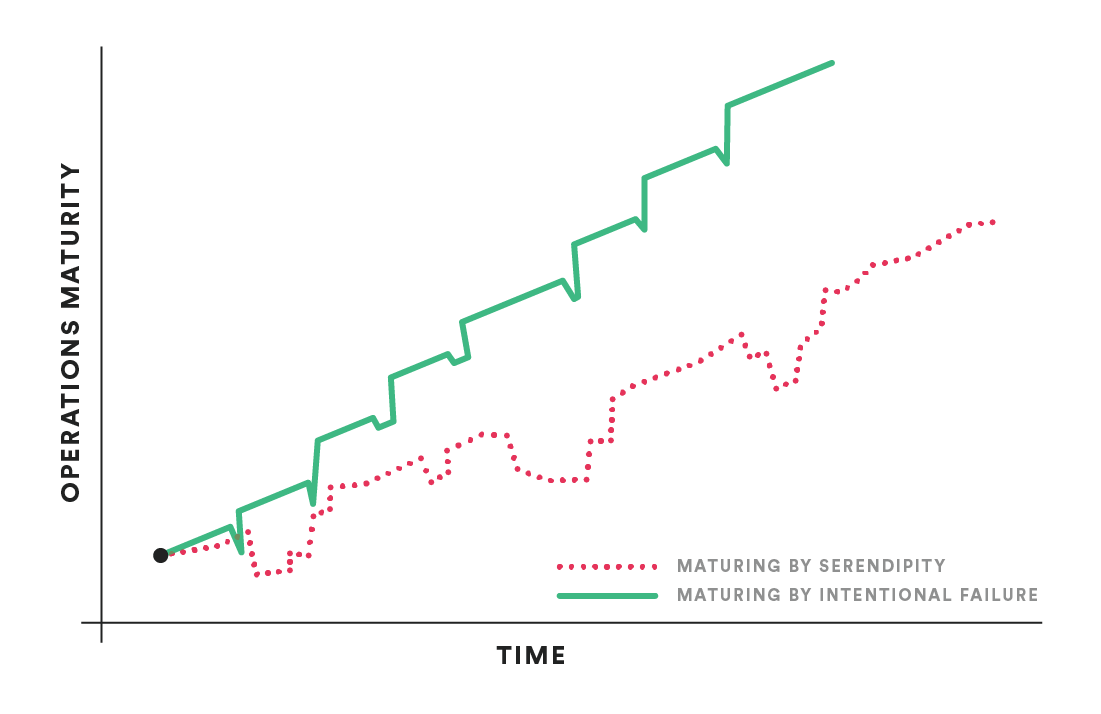
Operations teams mature and learn from failure, whether they are traditional ops or DevOps. We can let this happen by serendipity, when unexpected production failures happen and are fixed. Better yet, we can accelerate this maturing process by inducing failure in small ways and learning from it.
You get better at responding to fires each time they happen. You always learn something new. However, we would rather not burn down a building or cause catastrophic damage to get this information, and there is no need to wait for spontaneous combustion to cause late night pager calls to engineers. Gremlin helps companies figure out how to safely design chaos experiments and learn through failure while also helping our teams mature more quickly and intentionally. This helps all of us make our systems more reliable and our customers happier, and that is what we really want.

