
2023 is coming to a close and the holiday season is here, but that doesn’t mean things at Gremlin are slowing down. In fact, we’ve released a ton of new features and improvements to make testing and improving reliability even easier. Now you can run Chaos Engineering experiments in serverless environments, create custom reliability test suites, create more flexible Scenarios, and more easily identify critical components in your environment.
Keep reading for a look at what’s new in Gremlin.
New features
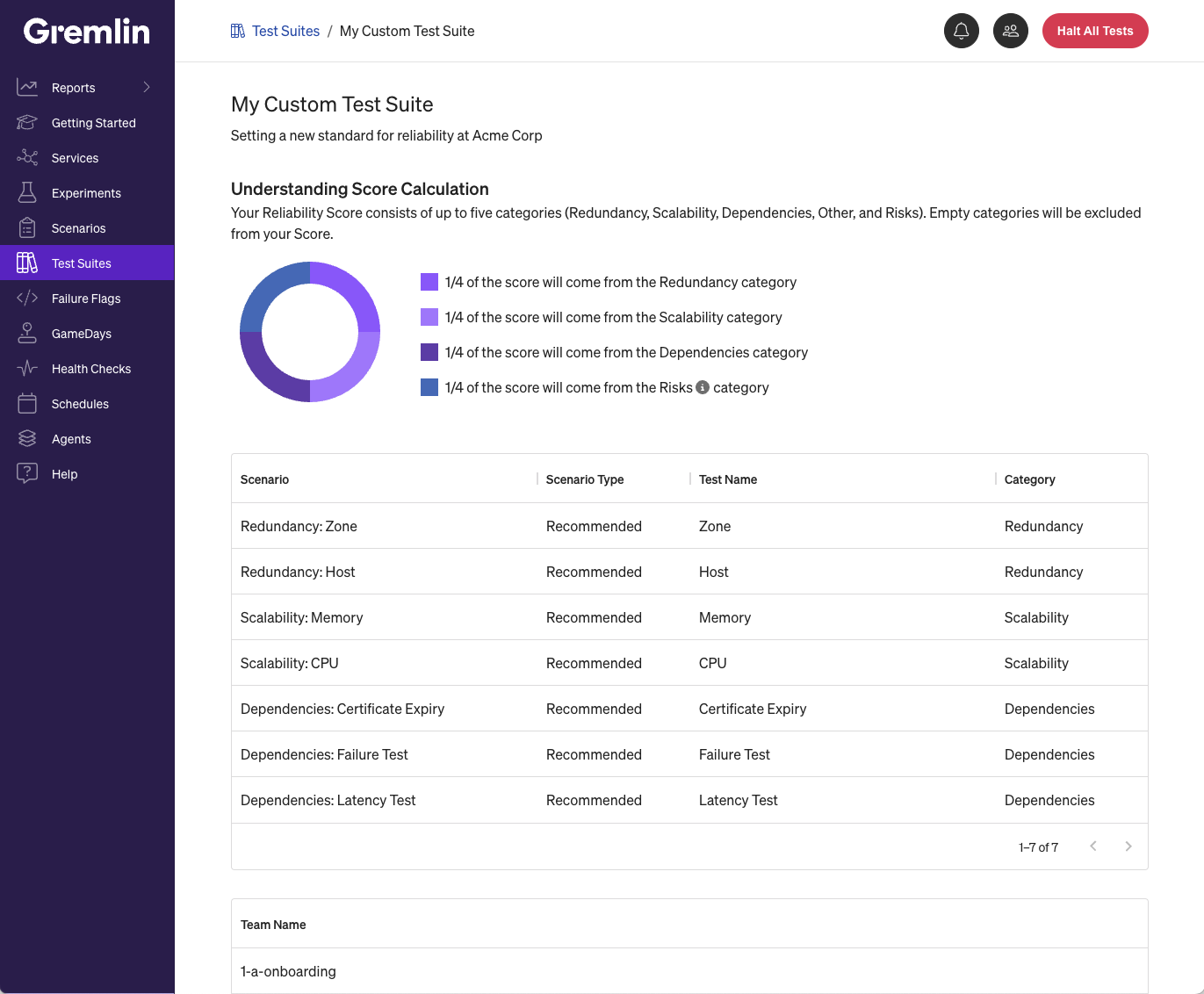
Set your own reliability standards with custom test suites
You can now create and run your own custom test suites! When we first launched Reliability Management, we created a single universal test suite based on reliability best practices. However, not all teams have the same requirements. Now, you can create your own suite of reliability tests consisting of one or more Scenarios.
Teams can now tailor their services, reliability scores, and reports around the tests that are important to them. Use them to set a bar for internal governance and meet external compliance requirements. Assigning a test suite to a team is easy and instantaneous, and Gremlin preserves your test history between test suites so you’ll always have a record of which tests you’ve run.
Build testable, reliable software—without touching infrastructure
In September, Gremlin launched the beta of Failure Flags, our new framework for running Chaos Engineering experiments at the application layer on Kubernetes and fully managed platforms such as AWS Lambda. We’re proud to announce that Failure Flags is now generally available to all Gremlin users!
Just as Feature Flags enable software teams to safely roll out new features at specific points in their software, Failure Flags enable those same teams to safely inject fault conditions into their applications to understand how they perform under nonideal conditions. It’s perfect for enabling software and QA teams to create and run tests, and for testing in environments where you don’t have access to the underlying infrastructure. Failure Flags brings Gremlin’s safe and secure fault injection tools to your Node.js, Java, Python, and Go applications. Read the blog post for more details.
Making Detected Risks a more integral part of your reliability practice
We launched Detected Risks in August, which automatically detects reliability issues in your environment without having to run Chaos Engineering experiments or reliability tests. Since then, we’ve made Detected Risks a part of the reliability score, which means a service’s reliability score will be lowered for each at-risk item detected by the Gremlin agent. Teams can use the Team Risk report to review unaddressed risks for each of their services, then increase their score simply by deploying fixes. The Gremlin agent will detect any mitigations and update the score automatically.
We’ve also added several new Kubernetes-specific risks that detect containers that fail to deploy. We will detect containers that have a status of CrashLoopBackOff or ImagePullBackOff. This makes it easier to identify deployment problems while also factoring container health into your service reliability scores.

Create more comprehensive tests with Scenario improvements
We’ve made many improvements to Scenarios, including the ability to run multiple Chaos Engineering experiments in parallel. Scenarios now have a comprehensive branching mechanism built-in, making it easier to recreate complex failure modes involving multiple simultaneous failures. When paired with the new custom test suites feature, this makes it possible to run in-depth experiments such as cascading region failures as a regular part of your testing process.

Automate reliability testing as part of your CI/CD pipeline
Gremlin has always supported CI/CD integration via our REST API, and now we’ve made it easier to embed reliability testing into your existing workflows. We’ve released two example workflows showing how to incorporate a service’s reliability score into your CI/CD process: one for Jenkins, and one for GitHub actions.
Safer testing in production
Gremlin now lets you tag dependencies as single points of failure. While we encourage you to test production dependencies to get the most accurate insights, some dependencies are known risks and can’t be thoroughly tested. Flagging a dependency as a single point of failure in Gremlin excludes it from automatic testing. This way, you can safely schedule regular reliability tests on services that rely on that dependency.

Tag, categorize, and filter your services
Gremlin has supported flagging services as “production” since we first released Reliability Management last year. Now, we’ve expanded this functionality to allow for custom metadata. You can now tag your services by environment, application, region, zone, or any other metadata your team uses. You can use these tags to filter and search services in the services list and Company Summary report.

Agent Updates
Improved fault detection and tolerance
We’ve improved the way Gremlin agents handle failures when communicating with Gremlin’s backend systems (called the Control Plane). If an experiment impacted the connection between the agent and the Control Plane, it could have caused the experiment to fail. Now, the agent is much more fault-tolerant and will resend failed notifications when possible.
We’ve also improved the way the agent sends errors from container-targeting experiments to the Control Plane, making it easier to troubleshoot execution problems. We’ve also improved the logging output of the validation routine that the agent runs on startup. If the validation process fails, debug information will be printed to the daemon.log file.
Kubernetes optimizations
We’ve also made some behind-the-scenes changes to Chao, our Kubernetes agent. First, we added a small amount (5%) of jitter between intervals where the agent sends data to the Control Plane. This helps mitigate the risk of a “thundering herd” when multiple clusters restart at the same time. We also updated the agent to track the PodStatus attribute of pods in your cluster, which will be used for future Detected Risks.
In addition, our Helm chart now explicitly declares DAC_READ_SEARCH, which is required for discovering dependencies and running Certificate Expiry experiments. Most container runtimes already provide a superset of this capability (DAC_OVERRIDE) by default.
Try it for yourself
If you already have a Gremlin account, everything noted here is already available to you, as long as you have the latest agent installed.
If not, sign up for a free trial to start understanding and improving your reliability posture in minutes.

