
You'll often hear the term "containers" used to refer to the entire landscape of self-contained software packages: this includes tools like Docker and Kubernetes, platforms like Amazon Elastic Container Service (ECS), and even the process of building these packages. But there's an even more important layer that often gets overlooked, and that's container images. Without images, containers as we know them wouldn't exist—but this means that if our images fail, running containers becomes impossible.
In this post, we'll look at one of the most common symptoms of image failures in Kubernetes: ImagePullBackOff. We'll look at why it happens, how you can fix it, and how to avoid the problem in the future.
What is an ImagePullBackOff error and why is it important?
ImagePullBackOff is a status that occurs when Kubernetes tries to create a container for a pod using a base container image. Before we can describe the problem, let's look at how images and containers work in general.
How do container images work?
Before a container orchestration tool (Kubernetes, Docker, Podman, etc.) can create a container, it first needs an image to use as the basis for the container. An image is a static, compressed folder containing all of the files and executable code needed to run the software embedded within the image. For example, the official Bash Docker image is made up of:
- A base Alpine Linux installation.
- The latest version of Bash, which is downloaded from the GNU FTP site.
- Optionally, any patches or customizations to apply.
- A script to run the
bashcommand when the container starts.
You could create this image yourself, but the Bash developers host an already-built version on Docker Hub that you can use simply by adding image: bash:<version> to the container spec in your Kubernetes manifest. When you deploy the manifest, Kubernetes pulls the image from Docker Hub, stores it on the host, and uses it as the base for all Bash containers that use that specific image version.
As a side note: Images are immutable and can't be modified by a container. If a container changes its filesystem (e.g. by adding or removing a file), the change only exists until the container terminates.
Why does an ImagePullBackOff happen?
Normally, Kubernetes downloads images as needed (i.e. when we deploy a manifest). Kubernetes uses the container specification to determine which image to use, where to retrieve it from, and which version to pull. If Kubernetes can't pull the image for any reason (such as an invalid image name, poor network connection, or trying to download from a private repository), it will retry after a set amount of time. Like a CrashLoopBackOff, it will exponentially increase the amount of time it waits before retrying, up to a maximum of 5 minutes. If it still can't pull the image after 5 minutes, it will stop trying and set the container's status to ImagePullBackOff.
How do I troubleshoot and fix an ImagePullBackOff?
If you're getting an ImagePullBackOff, here are some things to try:
- Double-check where the image is hosted. Kubernetes checks Docker Hub by default, so if you just provide a container name and version, Kubernetes assumes it's hosted on Docker Hub. If it's hosted elsewhere, like Google Artifact Registry or Amazon Elastic Container Registry, you'll need to provide the full URL.
- Make sure the container name is spelled correctly. Typos don't just prevent images from downloading, but they're also common vectors for malware in a practice known as typosquatting. If you specified the image version (which you should as a best practice), double-check to ensure the version label/digest is valid. Keep in mind that the image maintainer can remove older versions from the image registry if they choose, so older or outdated versions won't be available indefinitely.
- Make sure your Kubernetes nodes have network access to the image repository. Each node (or kubelet) is responsible for pulling its own images. If the kubelet is behind a firewall that blocks outbound traffic, it won't be able to pull the images it needs to run containers. If you can't expose your kubelets to the same network as the image registry, one option is to host your own private internal container registry and mirror any necessary images to that private repo so your kubelets can access it.
- Pre-pull images onto the nodes that need them.
- Check your container's
imagePullPolicy. If it's set toNeverand you haven't pre-pulled the image, the kubelet will never try to pull the image and will fail.
If none of these options works, there may be a problem with the image registry itself.
How do I ensure my fix works?
Once you've updated your manifest, re-deploy it, and monitor its progress using the Kubernetes command-line, Kubernetes Dashboard, or your tool of choice. Does the container start up? If not, repeat the steps in the previous section to see if the problem lies somewhere else.
Tools like the Kubernetes Dashboard will also highlight failed image pulls, and if you use an observability solution that supports Kubernetes, chances are it will also identify ImagePullBackOff events. Datadog, for example, has a Kubernetes operator for alerting on ImagePullBackOff as well as CrashLoopBackOff.
If you use a tool to verify Kubernetes manifests before deployment, some of those may also be able to identify misspelled or invalid image names. For example, Kubescape is an open-source tool that can perform security and misconfiguration scanning. It has hundreds of checks it can make, including whether your images are formatted correctly, come from a trusted image registry, and don't use insecure practices.
Lastly, if you're using Gremlin's Detected Risks feature, these steps are already being done for you. As long as the pod is part of one of your team's services, Gremlin will detect it the moment it fails to pull the image and display it in the Team Risk Report. You'll also see it if you open the service's page in the Gremlin web app and select Detected Risks.
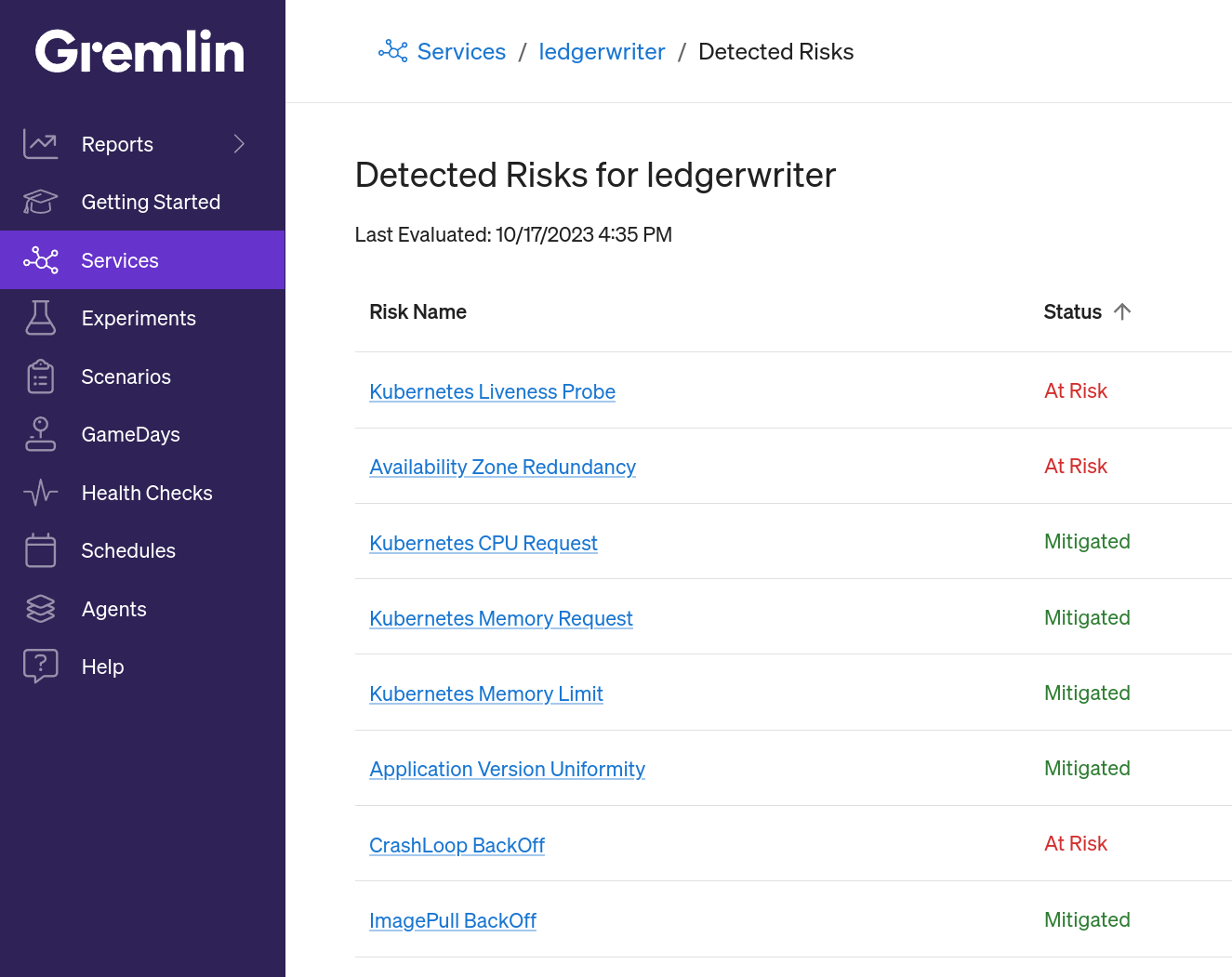
What other Kubernetes risks should I be looking for?
If you want to know how to protect yourself against other risks like resource exhaustion, missing liveness probes, and improperly configured high-availability clusters, check out our blog series on Detected Risks. Each post will walk you through a specific risk, how to detect it, how to resolve it, and how to prevent it from reoccuring.
In the meantime, if you'd like a free report of your reliability risks in just a few minutes, you can sign up for a free 30-day Gremlin trial.

