It's one of the most dreaded words among Kubernetes users. Regardless of your software engineering skill or seniority level, chances are you've seen it at least once. There are a quarter of a million articles on the subject, and countless developer hours have been spent troubleshooting and fixing it. We're talking, of course, about CrashLoopBackOff.
While nobody likes seeing CrashLoopBackOff in their Kubernetes event logs, it's not as dire as you might think. While Kubernetes is complex and often esoteric, you can always find the root cause of a crash loop as long as you know where to look. And in many cases, fixing a crash loop in one pod can help with fixing or preventing crash loops in other pods. In this blog, we'll explore why CrashLoopBackOffs happen, what you can do to fix them, and how you can avoid them in your next Kubernetes deployment.
What is a CrashLoopBackOff event and why is it important?
CrashLoopBackOff is the state that a pod enters after repeatedly terminating due to an error. Normally, the process for deploying a pod is relatively straightforward. After you define and deploy a pod manifest, Kubernetes assigns the pod to a host to run on, deploys it, and monitors it to ensure the container(s) within the pod run without errors. However, if a container crashes, Kubernetes waits for a short delay and restarts the pod.
The time between when a pod crashes and when it restarts is called the delay. On each restart, Kubernetes exponentially increases the length of the delay, starting at 10 seconds, then 20 seconds, then 40 seconds, etc., up to 5 minutes. This is an exponential back-off delay. If Kubernetes reaches the max delay time of 5 minutes and the pod still fails to run, Kubernetes will stop trying to deploy the pod and gives it the status CrashLoopBackOff. This happens if the pod's restart policy is set to Always (which is true by default) or OnFailure.
CrashLoopBackOff can have several causes, including:
- Application errors that cause the process to crash.
- Problems connecting to third-party services or dependencies.
- Trying to allocate unavailable resources to the container, like ports that are already in use or more memory than what's available.
- A failed liveness probe.
There are many more reasons why a CrashLoopBackOff can happen, and this is why it's one of the most common issues that even experienced Kubernetes developers run into.
How do I troubleshoot a CrashLoopBackOff?
Unfortunately, there's no one universal fix for a CrashLoopBackOff other than finding out why the pod and/or container failed. As a start:
- Examine the state of your pod using
kubectl describe pod [pod name]and look for relevant configurations or events that contributed to a crash. Under the Events heading, you'll see the message "Back-off restarting failed container" as well as any other events relevant to the problem. - Examine the container output or log file for your application to identify any error messages or crashes. You can use
kubectl logs [pod name]to retrieve the logs from the pod, or if the pod has already crashed and restarted, usekubectl logs --previous [pod name]. Frontends like K9s or the Kubernetes Dashboard can also help you discover and drill down into logs.
Once you've identified the reason for the crash loop, make any relevant fixes in your application code, container image, or deployment manifest. If it's an application error, update your application, rebuild the container image, then try re-deploying it. If it's an error with resource allocation, try increasing the pod's resource requests and/or resource limits so it has enough capacity to run for its entire lifecycle. Crash loops can also be caused by liveness probes. If your pod takes a long time to start, consider adding a startup and readiness probe to delay the liveness probe until the application has fully started.
If the problem is caused by a missing dependency or missing resource, particularly a cloud service, you could use an init container to wait for the resource to become available before the pod fully enters its running state. This doesn't address the problem of unreliable dependencies, but it will at least prevent your own application from crashing.
How do I ensure my fix works?
Verifying your fix is simple: when you re-deploy your pod, does it start up successfully? More specifically, does it enter the Running state and remain there? If not, repeat the steps in the previous section to troubleshoot the problem again.
While it's hard to prevent a CrashLoopBackOff, the next best thing is to set up a monitoring solution to detect them as fast as possible. If you have an observability tool, create an alert to notify you as soon as any pods enter a CrashLoopBackOff state. Tools like the Kubernetes Dashboard will also highlight failed pods so they're easier to identify. Your observability solution also likely has a feature for detecting crashed pods, as long as it supports Kubernetes. Datadog, for example, provides a Kubernetes operator for alerting on CrashLoopBackOff pods. The Kubernetes Dashboard and similar tools will also highlight crashed pods, but may not be able to send alerts or notifications like a full observability tool.
If you're using Gremlin's Detected Risks feature, these steps are already being done for you. As long as the pod is part of one of your team's services, Gremlin will detect it the moment it starts to crash loop and display it in the Team Risk Report. You'll also see it if you open the service's page in the Gremlin web app and select Detected Risks.
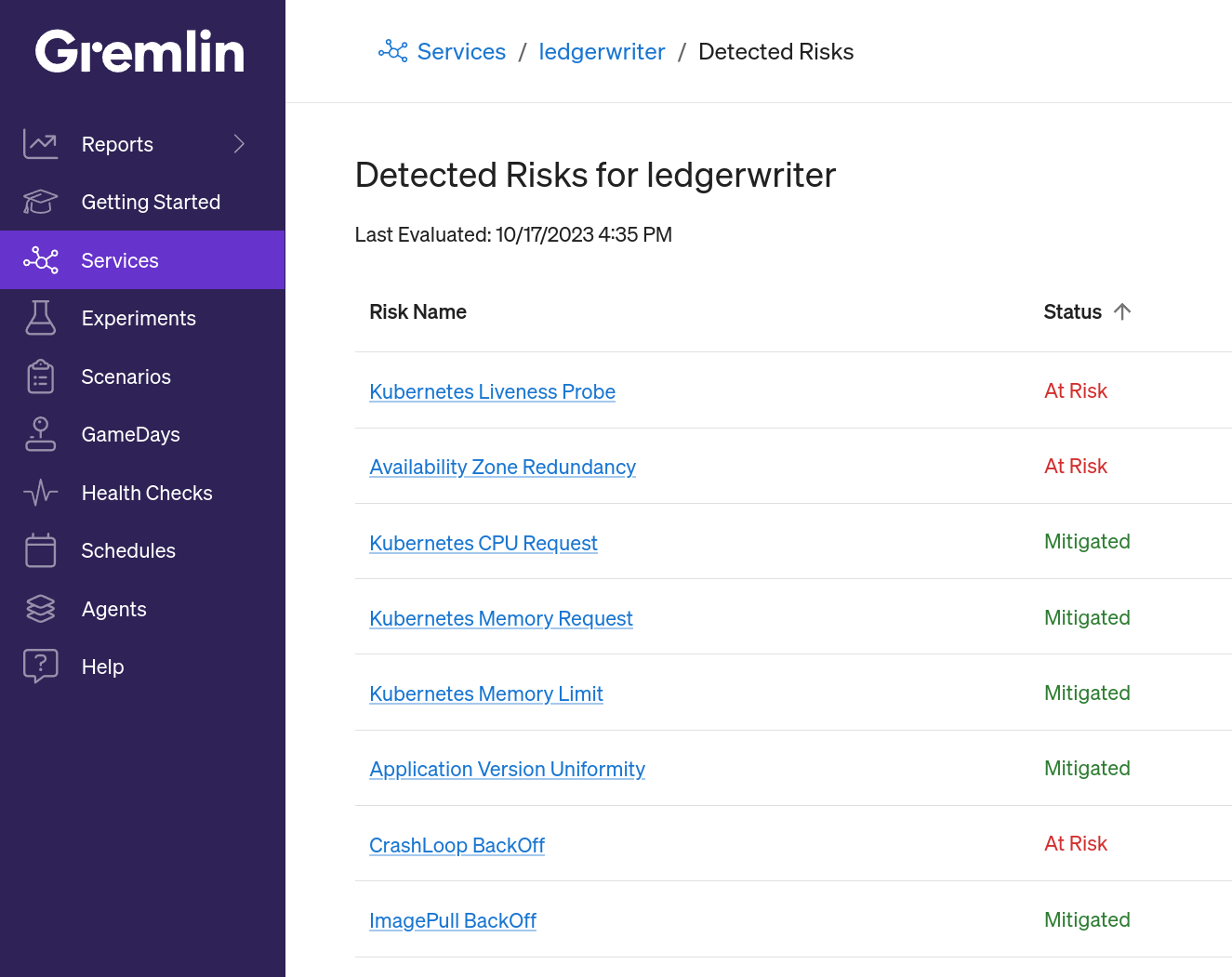
What other Kubernetes risks should I be looking for?
If you want to know how to protect yourself against other risks like resource exhaustion, missing liveness probes, and improperly configured high-availability clusters, check out our blog series on Detected Risks. Each post will walk you through a specific risk, how to detect it, how to resolve it, and how to prevent it from reoccuring. Our next blog in this series will cover the ImagePullBackOff status, so stay tuned!
In the meantime, if you'd like a free report of your reliability risks in just a few minutes, you can sign up for a free 30-day Gremlin trial.

