
You might be familiar with GameDays at this point. From watching our Introduction to GameDay webinar, viewing our Demo video, and reading our tutorial, you’ve probably learned that GameDays were created with the goal of increasing reliability by purposely creating major failures on a regular basis. Better yet, perhaps your own team has run a GameDay and learned something new about their services’ behavior during failure scenarios. At this point, you might be wondering, “How does Gremlin run their own internal GameDay?”
To constantly improve our own reliability and durability, one of our focuses is ensuring we consistently practice impactful GameDays internally here at Gremlin. We have a goal of running at least one GameDay a month. Having them consistently not only means they are executed quicker and we are able to prioritize resolving any postmortem tickets that arise, but also that the entire Gremlin team can see and experience a GameDay. That's right, we open our GameDays to the whole company. Inclusivity increases the diversity of perspectives, and expands the number of unique observations about our systems. Everyone has a role to play when it comes to observing system behavior and identifying trends.
Gremlin believes that the spirit of a Gameday is to challenge assumptions about a given service or distributed system through concrete discussion and thoughtful experimentation. Gamedays are not just for large organizations, or for dedicated SRE teams. Every team holds assumptions about a system’s behavior, and GameDays are a useful tool for testing the assumptions you’re aware of, AND the ones you took for granted.
Gremlin’s GameDay
We focus on 3 overarching headlines throughout the GameDay process: Prepare through a PreGame, Execute through a GameDay, and Learn through findings.
Naturally, we use Gremlin’s GameDay as a Service tool to accomplish these tasks. The GameDay feature was created after noticing our own shortcomings with running GameDays and from feedback by other Gremlin users. Having all aspects of a GameDay within the app, from establishing goals, to capturing learning and creating incident tickets, has drastically reduced our prep, execution, and follow up time, allowing for more consistent GameDays.
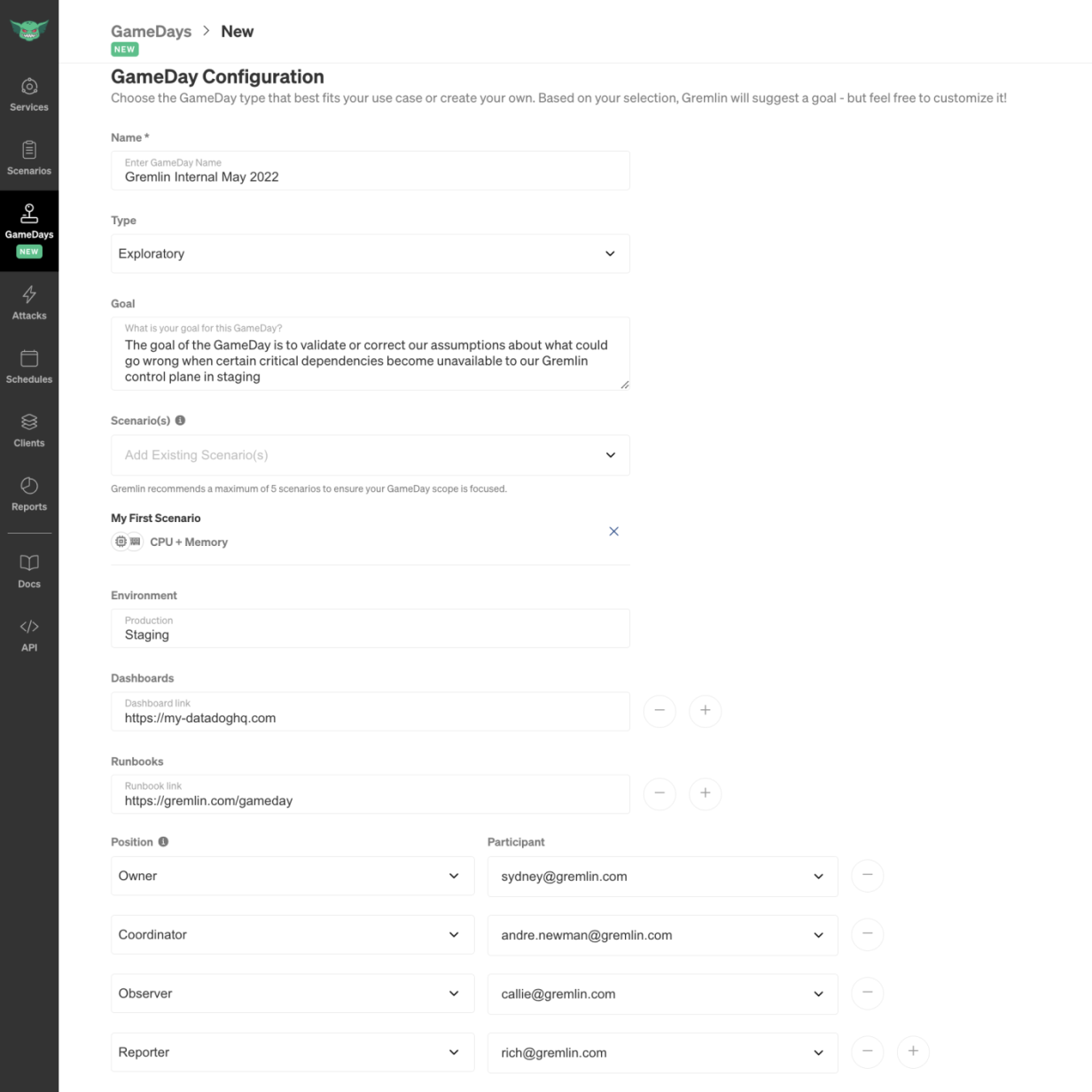
PreGame
We accomplish a lot, very quickly during our PreGame. The more GameDays you run the more familiar your team will be with the process and the easier set-ups will be. A unique part of our preparation is creating and filling out a GameDay template with the hypothesis, methodology, and background of the problem, all geared towards the company at large. This template becomes the working document during GameDays to house any extra information.
Our PreGame checklist includes:
- Create a #gameday Slack channel
- Create a calendar invite, include the Zoom room link, and invite the whole company to watch
- Decide on the Goal and Environment for the GameDay (sometimes we run more than one GameDay a session!)
- Use Gremlin to automatically validate our agents’ health
- Create Scenarios we want to test
- Create a Datadog Dashboard for the GameDay
- Assign GameDay Positions: Owner, Coordinator, Observer, or Reporter. You can find descriptions of each role in the Gremlin glossary.
- Fill out a new GameDay Template
GameDay Execution
This is the exciting part! As a remote company, we gather virtually in a Zoom room and Slack channel to execute our GameDay. After a quick check to make sure everyone has a full cup of coffee, it's time to begin. The Coordinator, responsible for initiating GameDay and preparing the experiment, takes ownership of the screen, showing the Gremlin web app and making sure the session is being recorded. It’s time to begin as we start to run the Scenarios. The Observer closely watches their observability tool to determine the impact of the Scenario on the system and shares any interesting or unusual behaviors. After the Scenario is complete (or halted by the Owner), the team discusses the results and Reporter fills out the “Scenario Completed” card, including attaching any important screenshots.
As Jira users, we utilize the end-to-end Jira integration by immediately creating a ticket in GameDay for any issues found. This enables our engineering team to resolve the discovered issues quicker and we can see if tickets are outstanding before re-running or creating a new GameDay.
This process is repeated for the remaining Scenarios. After all Scenarios are run, the Summary page is filled out with notes, action items, and any final attachments and Jira tickets. We’ll kick off our next GameDay by rerunning this one, confirming any previous impacts are resolved.
Learn through Findings
We have lively discussions during our GameDays, engaging in conversations during and after the attacks. If there is a failure, we discuss in-depth what happened, why it happened, and the follow up needed. In addition to the Jira ticket, this could include monitoring changes or an item added to the runbook.
It is equally important for us to discuss tests that resulted in no impact. If a test previously showed an impact, but did not during the following tests, we take the time to applaud the fix that was rolled out to mitigate the failure state. Additionally, we might decide to set up a GameDay of now-fixed, formally impacted tests to regularly review so that subsequent builds don't introduce regression.
Conclusion
Running your own GameDay to practice Chaos Engineering, test your incident response process, validate past outages, or find unknown issues in your services is necessary to having a reliable platform. We look forward to completing at least 12 GameDays this year and hope you'll join us in our efforts in creating a more reliable internet.

